



How to extract features from the text for sentiment analysis: A Beginner's Guide to Making Sense of Text Data to computer"
Extracting features from a tweet


Hey humans 👋, this is my first blog in the NLP series.
Have you ever wondered how your favorite brands and companies measure your feelings about their products and services? Well, they use a powerful technology called Sentiment Analysis. In Natural Language Processing (NLP), sentiment analysis is the process of analyzing text data to determine the sentiment or opinion expressed within it. It is a vast domain, in this blog I will be explaining simple Positive and Negative sentiment representation.
In Natural Language Processing (NLP), a corpus and vocabulary are two important concepts that play a crucial role in understanding and processing text data.
Corpus
A corpus is a large and structured set of text data that is used for language analysis and processing. This can be any collection of written or spoken language, such as books, articles, news feeds, tweets, or even transcripts of speeches. The purpose of creating a corpus is to provide a representative sample of the language being studied, which can be used for analysis and research.
Following is an example of the corpus that we will be using for today's exercise.

The corpus contains positively and negatively labeled texts.
Vocabulary
A vocabulary, on the other hand, is the set of unique words that appear in a corpus. It is a crucial component of any NLP system because it is used to represent and process text data. The size and quality of the vocabulary can have a significant impact on the accuracy and effectiveness of an NLP system.
Here's the vocabulary of our corpus.
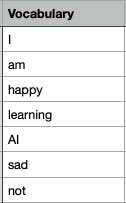
The process of creating a vocabulary involves tokenizing the text data, removing stopwords (common words like "the" and "is" that don't carry much meaning), and stemming (reducing words to their root form). The resulting set of unique words is then used as the vocabulary for the NLP system. These concepts will be covered in upcoming blogs.
Word frequency class
In Natural Language Processing (NLP), word frequency classes are used to group words based on their frequency of occurrence in a corpus. This can be useful for various NLP tasks, such as text classification, topic modeling, and information retrieval.
Here's the word frequency class for our corpus. These are positive and negative frequency counts.
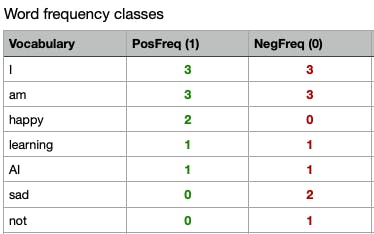
In practice when coding, this table is a dictionary mapping from a word class there to its frequency. So it maps the word and its corresponding class to the frequency or the number of times that's where it showed up in the class.
Now let's see how we can extract useful features for sentiment analysis. We will use the following formula.
Before that have a quick look at what the V-dimension vector is.
Tweet = "I am happy"
given tweet will a v dimensional vector like this 👇

A small relative non-zero value is called a sparse representation.
Problems with sparse representation
If the corpus is big, then the training time will be large and it will take much more time to make a prediction.
Feature Extraction
You previously learned to encode a tweet as a vector of dimension V. You will now learn to encode a tweet or specifically represented it as a vector of dimension 3.
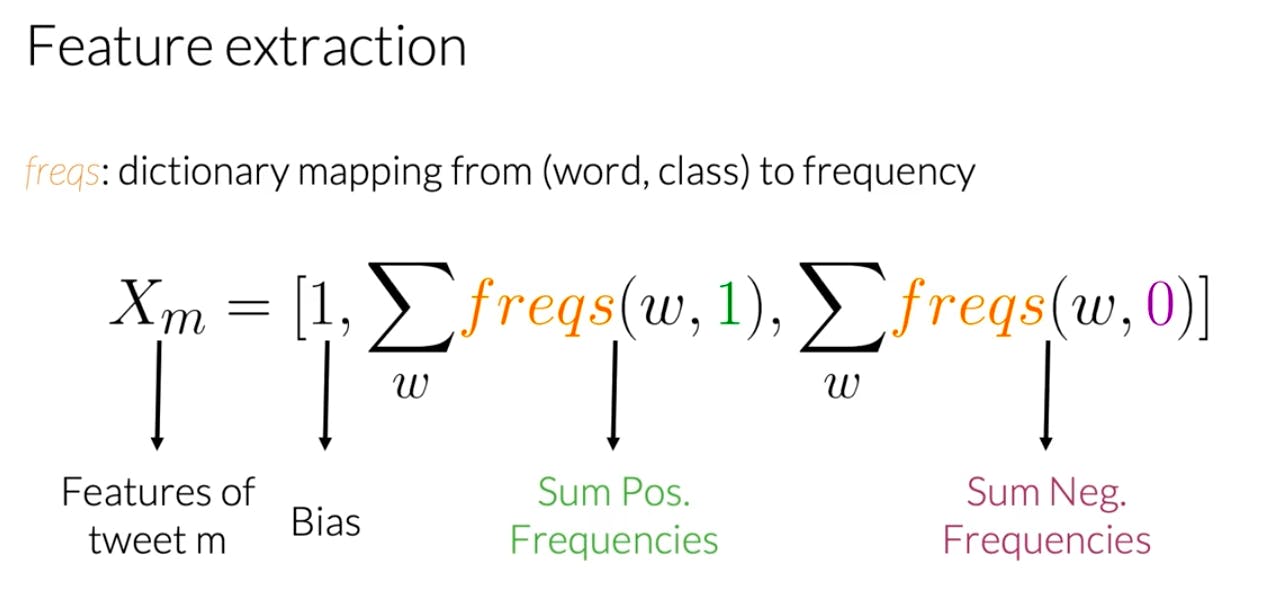
Now we will calculate the sum of positive frequencies and the sum of negative frequencies.

We get the feature of Tweet like this ⬇︎
$$Xm = [1,8,9]$$
Thank you for reading 😁.
For more such content make sure to subscribe to my Newsletter here
Follow me on