




Do you know what vector databases and embeddings are? If not, you're missing out on a game-changing technology that's revolutionizing the way we process and search for complex data.
Vector Embeddings
Traditional databases are not suitable for large amounts of complex data like images or PDFs, and performing a search operation on such data using traditional databases is impossible. This is where vector embeddings come in. They represent complex data such as words or images as a series of numbers or vectors. These vectors can be created using machine learning algorithms that analyze large amounts of data to learn how to represent it in a lower-dimension space.
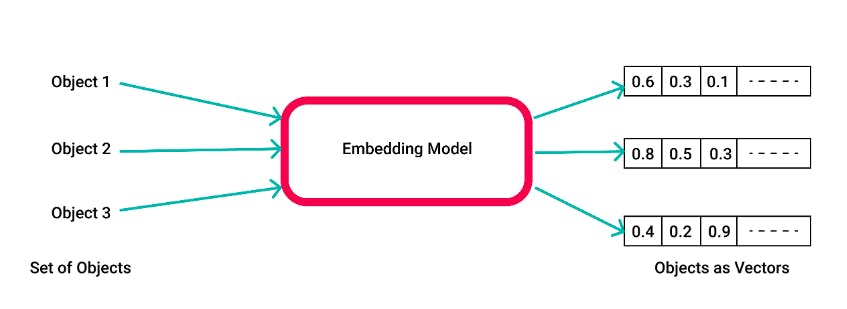
Vector Database
But why are vector databases important? Well, they enable semantic search, allowing us to find similar meanings in the text. For example, the words "helicopter" and "plane" would be placed closer together in a vector database because they are similar in meaning.
Vector databases and embeddings are all the rage in AI right now, with companies like Pinecone scoring $100M at a $B valuation. Even the latest AI tools like Midjourney and ChatGPT are using them.
How Vector DB works?
So how do vector databases help with the limitations of language models?
Let's say you have a massive PDF, but the language model you're using can only handle a limited number of tokens.
Simply chunk up the PDF and create a vector embedding for each chunk.
Then, ask a question and make a vector embedding of it as well.
Compare the vectors using cosine metric in a process called "similarity search."
The three chunks whose vector embeddings are most similar to the question embedding can be fed into the language model, allowing you to process a large amount of text without passing all of it into the language model.
And here's the fun part: the secret sauce behind those "chat with your site/pdf/blah blah" services is essentially this process of using vector embeddings and databases to process large amounts of text!
Vector databases and embeddings may sound complex, but they are incredibly useful for enabling semantic search and processing large amounts of complex data. And who knows, with the help of vector databases and language models, maybe we'll finally be able to crack the code on the ultimate joke 😬!
Thank you for reading 😁.
If you like my work, you can support me here: Support my work
I do welcome constructive criticism and alternative viewpoints. If you have any thoughts or feedback on our analysis, please feel free to share them in the comments section below.
For more such content make sure to subscribe to my Newsletter here
Follow me on